
Meta heeft een open-source model uitgebracht dat de concurrentie kan aangaan met GPT-4, GPT-4o en Claude 3.5 Sonnet. Het grote verschil: Meta kiest bij Llama 3.1 voor een open benadering, terwijl de concurrerende topmodellen closed-source zijn. Bij closed-source kunnen de modellen alleen aangeroepen worden via een betaalde API. Zullen developers straks hoofdzakelijk open-source AI gebruiken?
Met 405 miljard parameters is Llama 3.1 zeer capabel. Dit aantal zegt iets over hoe goed het model gedetailleerde, complexe opdrachten kan oppakken. In theorie maakt 405 miljard parameters de output zeer nauwkeurig. Vergelijkingen met GPT-4, GPT-4o en Claude 3.5 Sonnet zijn echter lastig te maken, simpelweg omdat het exacte aantal parameters van deze modellen niet bekend is. Maar de benchmarks die we later in dit artikel bespreken, geven wel een indicatie van de nieuwe verhoudingen in de markt.
Meta-CEO Mark Zuckerberg voorziet grote veranderingen in de developer community dankzij wat Llama 3.1 bereikt. “Ik geloof dat de release van Llama 3.1 een keerpunt zal zijn in de industrie, waar de meeste ontwikkelaars voornamelijk open-source gaan gebruiken,” aldus Zuckerberg. Volgens hem is open-source belangrijk voor het uitbouwen van een ecosysteem, het garanderen van veiligheid en de verdere ontwikkeling van het model.
We moeten echter opmerken dat, hoewel een groot model in eerste instantie zeer interessant is, er ook nadelen aan kleven. Een dergelijk model vereist namelijk veel compute-resources en energie. Meta verbruikte zelf al 30,84 miljoen GPU-uren en produceerde 11.390 ton CO2-uitstoot voor het trainen van het model. Bovendien is de schaal voor de gemiddelde ontwikkelaar te uitdagend om mee te werken.
Let op, we bespreken in dit artikel enkel Llama 3.1 405B en niet de kleinere modellen 70B en 8B.
Hoe presteert Llama 3.1?
Het meest interessante aspect om nu te beoordelen zijn de prestaties van Llama 3.1, door naar de benchmarks te kijken. Die zijn hieronder te vinden. In de markt worden taalbegrip, programmeren en wiskunde over het algemeen gezien als de belangrijkste competenties van een model. In die categorieën zijn MMLU, Human Eval en GSM8K respectievelijk de standaarden. In de categorie taalbegrip zijn er cijfermatig in de benchmarks weinig verschillen. Coderen doet Claude 3.5 Sonnet echter aanzienlijk beter. Het verschil in wiskunde is ook klein, al scoort Llama 3.1 hier nipt het best.
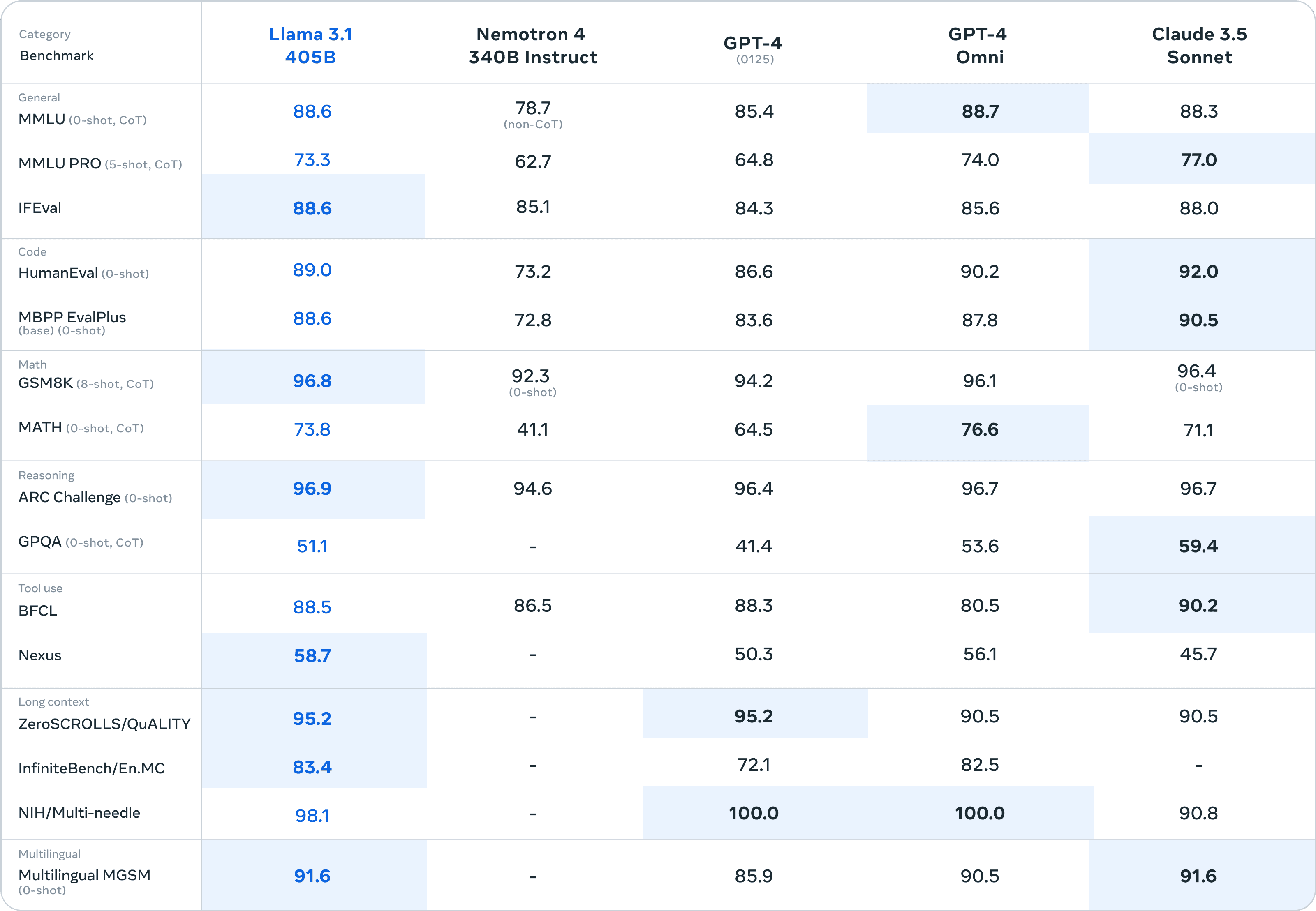
Waar het nieuwe Meta-model aanzienlijk beter in presteert, is in lange contexten en beredenering. Dit kan deels worden verklaard door de 405 miljard parameters, die in dergelijke situaties van pas komen. Voor alle benchmarks geldt uiteindelijk dat ze een betrouwbare indicatie geven; Meta evalueerde op basis van meer dan 150 benchmarkdatasets. Toch moet de praktijk uitwijzen hoe exact de prestaties zijn.
Meta bereikt nieuwe hoogten met decoder-only transformer
De benchmarks laten zien dat Meta, na eerdere Llama-versies, nu voor het eerst echt de concurrentie kan aangaan met de gesloten modellen van andere bedrijven. Wat naast de parameters bijdraagt aan deze prestatie, is de gekozen architectuur. Het betreft een decoder-only transformerarchitectuur, waarbij een prompt in zijn geheel wordt ingevoerd. Dit is anders dan de mixture-of-experts (MoE)-architectuur, die vaak wordt gekozen bij de nieuwste modellen. In dat geval wordt input geanalyseerd door verschillende experts die gespecialiseerd zijn in bepaalde taken, wat de output nauwkeurig maakt.
Meta geeft aan dat de uitdaging vooral zat in het trainen van Llama 3.1 op meer dan 15 biljoen tokens. Dit verklaart ook het hoge aantal GPU-trainingsuren. Meta gebruikte zelf meer dan 16.000 van de zeer krachtige Nvidia H100-GPU’s, wat de schaal van het project benadrukt. Het ontwikkelproces moest daardoor rechttoe rechtaan blijven, wat de keuze voor een standaard decoder-only transformer verklaart. Daarnaast volgde Meta een iteratieve post-trainingsprocedure, waarbij elke ronde gebruik maakte van supervised fine-tuning en directe voorkeursoptimalisatie. Hierdoor kon Meta in elke ronde synthetische data van de hoogste kwaliteit creëren en de prestaties verbeteren.
Al met al denkt Zuckerberg dat Llama 3.1 een vergelijkbare weg gaat bewandelen als Linux, dat ook een standaard is geworden voor developers. “In de begindagen van high-performance computing investeerden de grote technologiebedrijven van die tijd zwaar in de ontwikkeling van hun eigen closed-source versies van Unix. Het was destijds moeilijk voor te stellen dat een andere aanpak zulke geavanceerde software zou kunnen ontwikkelen. Uiteindelijk won open-source Linux echter aan populariteit – aanvankelijk omdat het ontwikkelaars in staat stelde de code aan te passen zoals zij dat wilden en omdat het betaalbaarder was, en na verloop van tijd omdat het geavanceerder en veiliger werd en een breder ecosysteem had dat meer mogelijkheden ondersteunde dan welke gesloten Unix dan ook. Tegenwoordig is Linux de industriestandaardbasis voor zowel cloud computing als de besturingssystemen waarop de meeste mobiele apparaten draaien.”
Llama 3.1 is per direct te gebruiken via de Meta AI-app. Aangezien het model nog in de previewfase zit, geldt voorlopig dat er slechts een beperkt aantal queries per week kan worden uitgevoerd. Er is nog geen ondersteuning voor de Nederlandse taal.