
Kort nadat Meta de AI-wereld opschudde komt Mistral met een nieuwe concurrent. Mistral Large 2, kleiner dan de 405 miljard parameters van Meta’s Llama 3.1, zou “groot genoeg” zijn. Is dat waar?
Allereerst valt een aantal gelijkenissen tussen Large 2 en Llama 3.1 op. Zo bevatten beide modellen een context window van 128K tokens. Ook de benchmarkscores van de LLM’s ontlopen elkaar nauwelijks. Ze blinken wel uit in verschillende velden, waardoor beide AI-spelers een use case in kunnen vullen.
Tip: Llama 3.1 is grootste model: keerpunt in open source AI?
Mistral Large 2 bevat 123 miljard parameters, dus ruim drie keer minder dan Llama 3.1. Toch laten de benchmarks zien dat competitieve prestaties mogelijk zijn met een kleiner model.
Goed in coderen
Mistral heeft al enige ervaring met gespecialiseerde codeer-LLM’s. Codestral 22B en Codestral Mamba leverden al superieure AI-programmeurs op tegenover Meta’s Code Llama. Nu overtreft Mistral Large 2 deze specialisten op het gebied van codegeneratie en wiskundige problemen. In HumanEval, een bekende AI-benchmark, hoeft het alleen GPT-4o van OpenAI voor zich te dulden. Large 2 excelleert met name in Java en scoort net iets lager dan GPT-4o met C++ en TypeScript. Voorganger Large 1 komt niet in de buurt: de gemiddelde score van 58,8 procent doet sterk onder voor de 74,4 procent van Large 2.
Taalknobbel
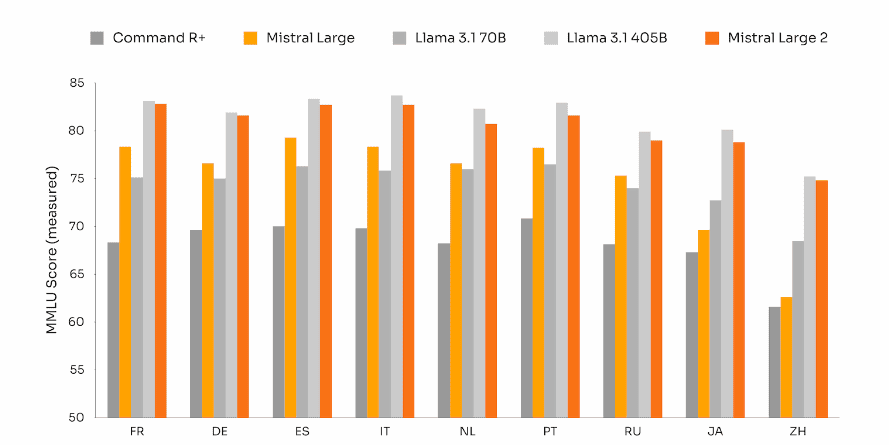
Llama 3.1 heeft 405 miljard parameters nodig om Large 2 te overtreffen, blijkt bij de Multilingual MMLU-benchmark. De variant met 70 miljard parameters legt het altijd af tegen Mistral Large 2, dat binnen een paar procent blijft bij de scores in verschillende talen.
Niet open-source
Hoewel onderzoekers Mistral Large 2 mogen gebruiken, is het niet daadwerkelijk open-source. Organisaties moeten voor professioneel gebruik of het voortbouwen erop aankloppen bij Mistral. Daarin verschilt de opzet met Meta, dat Llama 3.1 ook voor commercieel gebruik beschikbaar stelt.