
Het nieuwe Open Platform for Enterprise AI (OPEA) zal zich inzetten voor open-source AI-adoptie. De eerste taak zal zijn om open standaarden te ontwikkelen voor RAG, ofwel Retrieval-Augmented Generation.
OPEA is een product van de LF AI & Data Foundation, dat op de eigen beurt een spin-off is van de Linux Foundation sinds 2018. De doelstelling van de OPEA-initiatiefnemers is, niet geheel verrassend, precies wat de naam suggereert: het aanjagen van een open-source AI-ecosysteem voor het bedrijfsleven. Onder de 10 Premier-leden vallen onder meer AWS, Huawei, Intel, IBM, Microsoft en SAS.
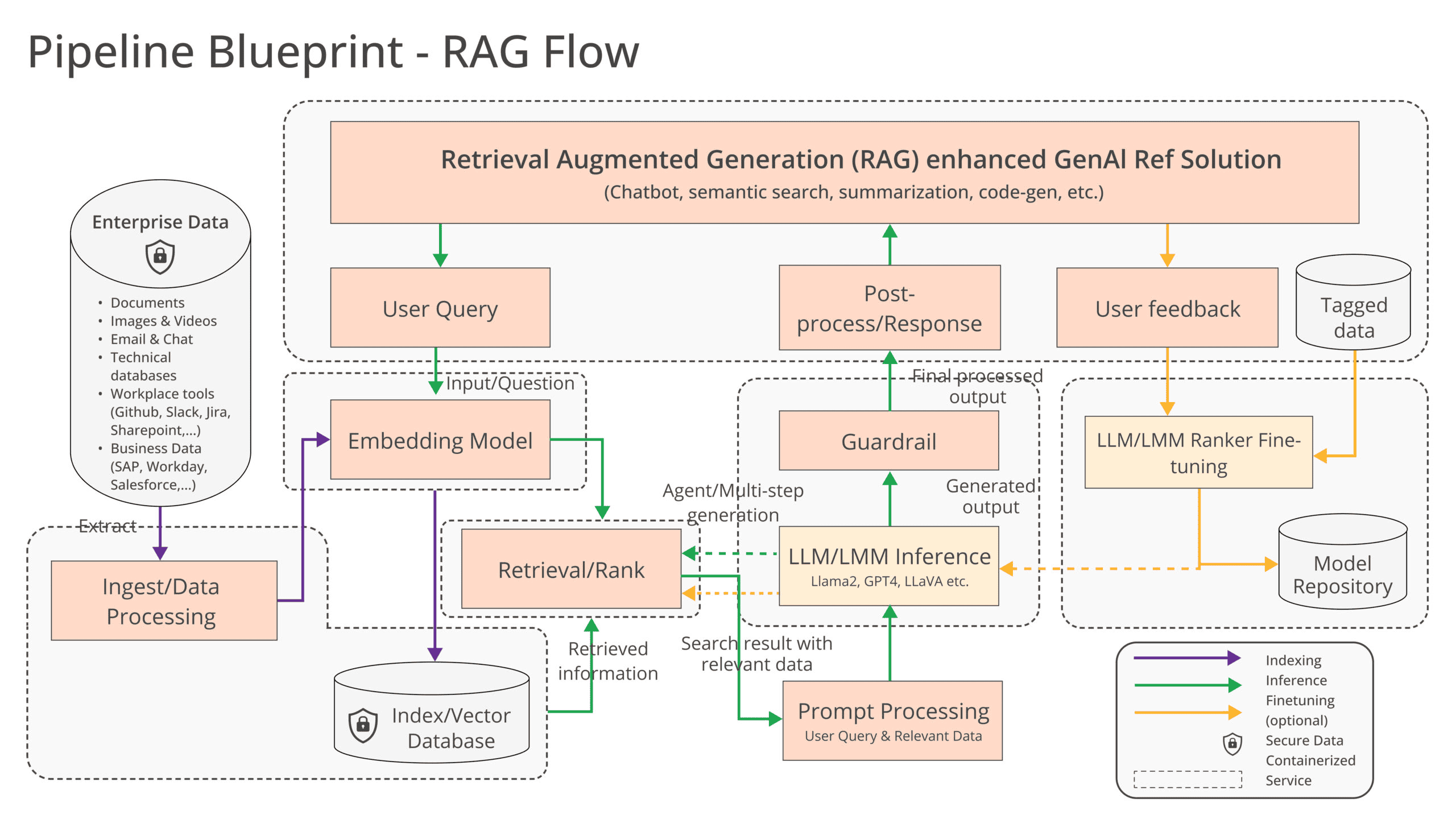
RAG geldt als een belangrijk middel om AI-modellen geschikt te maken voor de inzet binnen organisaties. Vooraf getrainde modellen kunnen met deze methode interne documenten inzien (retrieval) om hun AI-outputs (generation) te verrijken. Dit laat LLM’s de context van de eigen bedrijfsvoering vatten zonder dat modellen een tijdrovend en kostbaar trainings- of fine-tuningsproces hoeven te doorlopen. Het bijkomende voordeel is dat de data in real-time te updaten is, belangrijk voor bijvoorbeeld banken om de huidige financiële markt te kunnen analyseren.
Lees ook: Wat is RAG (Retrieval-Augmented Generation)?
Tegen de fragmentatie van tools
RAG is een goed AI- probleem om via OPEA aan te pakken, aangezien organisaties die twijfelen over AI-adoptie met de verhoogde accuratesse van deze methode overstag kunnen gaan. Toch is er op het gebied van generatieve AI nog veel te standaardiseren. Nu al is er sprake van een “fragmentatie van tools, technieken en oplossingen,” stelt de LF AI & Data Foundation. De doelstelling is daarom om “gestandaardiseerde componenten” te creëren “inclusief frameworks, architecturele blauwdrukken en reference-oplossingen”. Cruciaal daarbij is dat dit aanbod productiegereed is met de vereiste prestaties, interoperabiliteit en betrouwbaarheid.
Concurrentie voor het OPEA-initiatief is er zeker, en wel vanuit de proprietary-hoek. Daar waar bijvoorbeeld Intel en AMD hun AI-stack hebben gebouwd met open-source software en hardware die deze aanpak ondersteunt, kiest Nvidia voor eigen oplossingen op beide gebieden. Dit contrast is betekenisvol, aangezien laatstgenoemde de enterprise AI-wereld momenteel grotendeels in handen heeft. Het is aan alle andere partijen om ervoor te zorgen dat ontwikkelstandaarden als Nvidia’s eigen CUDA het geleidelijk zullen afleggen tegenover open standaarden.
Tip: Intel en Nvidia hebben radicaal andere visies op AI-ontwikkeling
Ecosysteem deels overstag
Het totale ledenbestand van de LF & Data Foundation is in ieder geval groot. Partijen als Anyscale, Datastax, Hugging Face, de MariaDB Foundation, Red Hat en VMware (by Broadcom) zullen allemaal bijdragen aan het initiatief. Het eindresultaat moet leiden tot “open, multi-provider, robuuste en composable GenAI-systemen”.
Tip: Databricks komt met DBRX: open-source LLM dat GPT-3.5 en Llama 2 verslaat