
Meta heeft recent zijn nieuwste early-fusion multimodale LLM in een onderzoekspaper gepresenteerd onder de naam Chameleon. Hiermee hoopt het bedrijf nieuwe AI-applicaties mogelijk te maken die zowel visuele als tekstuele informatie kunnen verwerken en genereren.
Meta zit niet stil in de AI-race en komt met Chameleon, een prototype van een ‘native’ multimodaal LLM. Native betekent in dit geval dat het al vanaf de start multimodaal is, in plaats van ‘late fusion’ multimodaliteit zoals in bijvoorbeeld DALL-E. In dat laatste geval worden verschillende componenten elk in andere modaliteiten getraind en later samengevoegd. Chameleon is dus al vanaf de start een multimodaal LLM, ofwel ‘early fusion’.
Dit betekent dat dit LLM in staat is direct de eerder door verschillende modellen uitgevoerde taken in één keer af te handelen en daardoor bijvoorbeeld in staat is verschillende soorten informatie beter en directer te integreren. Hierdoor kan het model bijvoorbeeld makkelijker opeenvolgingen van beelden of tekst of combinaties daarvan genereren. Zo stelt althans het onderzoekspaper, want Chameleon is nog niet uitgebracht.
Early-fusion-model
Meer specifiek gebruikt Chameleon van Meta een ‘early-fusion token-based mixed-modal’-architectuur waarbij het model vanaf de basis leert van een verweven combinatie van beelden, code, teksten en andere input. Beelden worden daarbij omgezet in discrete tokens, zoals taalmodellen doen met woorden. Daarnaast gebruikt het LLM een gemengde ‘woordenschat’ die bestaat uit beeld-, tekst- en code-tokens. Hierdoor is het mogelijk opeenvolgingen te maken die zowel beeld- als tekst-tokens bevatten.
Volgens de onderzoekers zou Chameleon het beste de vergelijking aankunnen met Google’s Gemini, dat onder de motorkap ook een early-fusion-benadering toepast. Het verschil is daarbij wel dat Gemini twee aparte beelddecoders gebruikt in de genereerfase, terwijl Chameleon een end-to-end-model is dat zowel tokens verwerkt als genereert.
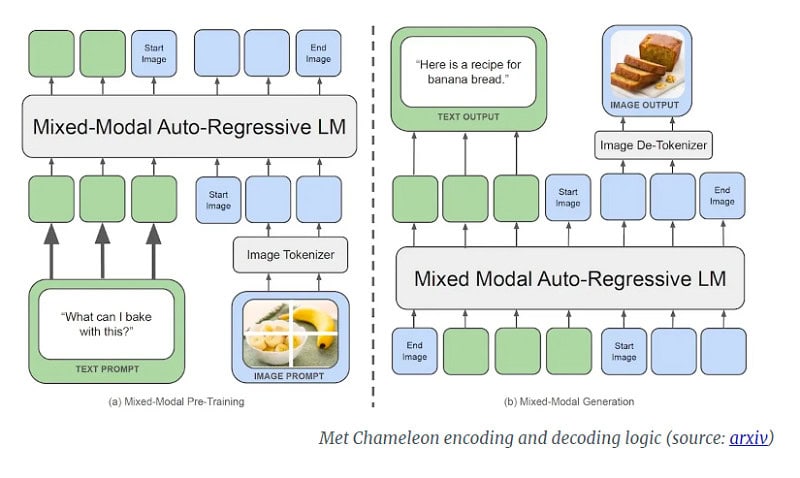
Training en prestaties
Early-fusion LLM’s zijn moeilijk te trainen en te schalen, maar de specialisten van Meta hebben hier naar eigen zeggen een antwoord op gevonden. Ze hebben in de architectuur van het LLM enkele aanpassingen gedaan en trainingstechnieken toegevoegd.
De training van het model vindt plaats in twee fases met een dataset van 4.4 biljoen tokens van tekst, beeld-tekstcombinaties en opeenvolgingen van verweven teksten en beelden. Hiermee werden twee Chameleon-versies getraind; één van 7 miljard parameters en één van 34 miljard parameters. De trainingssessie duurde meer dan 5 miljoen uur op Nvidia A100 80GB GPU’s.
Uiteindelijk leidden deze trainingssessies ertoe dat Chameleon van Meta verschillende tekst-only en multimodale acties kan uitvoeren. Op het gebied van visuele generatie presteert het LLM van 34-miljard parameters op basis van benchmarks beter dan LLM’s als Flamingo, IDEFICS en Llava-1.5.
Op het gebied van tekst-only generatie presteert het model op gelijke voet als Gemini Pro van Google en Mixtral 8x7B van Mistral AI.
AI-race gaat verder
De introductie van dit laatste LLM van Meta staat niet op zichzelf. Vorige week introduceerde OpenAI zijn nieuwste GPT-versie, GPT-4o. Microsoft introduceerde enkele weken geleden zijn MAI-1-model en Google lanceerde Project Astra dat ook de concurrentie met GPT-4o moet aangaan.
Wanneer het Chameleon LLM van Meta definitief wordt gepresenteerd, is nog niet bekend.
Lees ook: ChatGPT praat voortaan in real-time, nieuw model GPT-4o gratis beschikbaar