
Fujitsu heeft een nieuwe technologie aangekondigd die CPU’s en GPU’s optimaal benut. Processen die eenn hoge ‘execution efficiency’ hebben, krijgen voorrang. Het Japanse bedrijf hoopt organisaties uit de brand te helpen die worden geplaagd door het wereldwijde GPU-tekort, veroorzaakt door de alom aanwezige AI-hype.
Eerder dit jaar stelde Nvidia dat datacenters op de schop moeten. Meer GPU’s om intensieve workloads die daarvan afhangen, te ondersteunen. Fujitsu heeft echter een andere oplossing bedacht. Een duidelijke naam is nog niet bekend, maar men zal de technologie op den duur in een softwarepakket gaan leveren.
Benutten van CPU en GPU
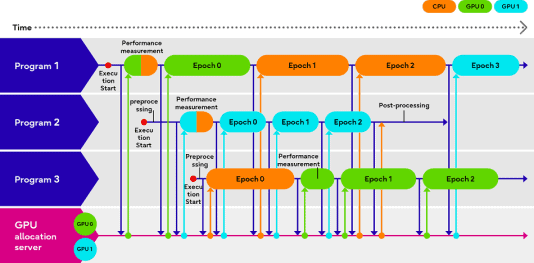
Allereerst spreekt Fujitsu over een technologie die CPU en GPU optimaal benut. Daarbij onderscheidt het programma’s die eventueel ook verwerkt kunnen worden door een CPU en andere die van GPU’s afhankelijk zijn. Men doet dit door te voorspellen hoeveel tijd de hardware-acceleratie kost per programma, waarbij GPU’s in real-time worden herverdeeld om programma’s met een hoge prioriteit te verwerken.
In het voorbeeld hieronder wil een gebruiker 3 programma’s verwerken met een enkele CPU en twee GPU’s. De twee GPU’s worden optimaal benut terwijl de CPU als een tweede optie te hulp schiet, zodat de totale tijd om de drie programma’s te verwerken geminimaliseerd wordt. Het alternatief zou vermoedelijk zijn dat een programma moet wachten tot een GPU vrijkomt, die eerst door twee andere programma’s worden bezet.
Minder wachten
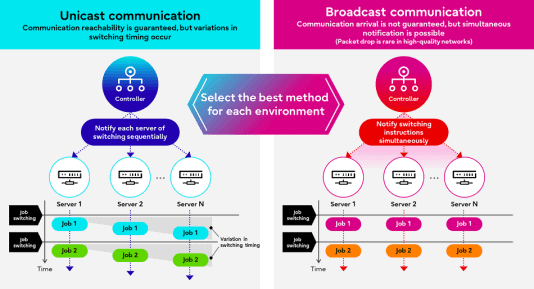
Een andere oplossing van Fujitsu is er een die het in real-time schakelen tussen meerdere programma’s sneller maakt. Een HPC-systeem met meerdere computers zou met deze technologie niet hoeven te wachten tot een programma afsluit om een andere op te starten. Daarmee wil Fujitsu het mogelijk maken om dergelijke HPC-systemen inzetbaar te maken voor het draaien van programma’s met restrictieve latency-eisen.
Fujitsu legt uit dat de conventionele communicatiemethode in een HPC-systeem veel inherente oponthoud kent. Dit komt door timing-verschullen in switching tussen servers. Deze methode staat bekend onder de naam ‘unicast’, en informeert elke server achter elkaar over een nieuwe switch. Dit is erg betrouwbaar, maar Fujitsu hoopt in selecte situaties seconden winst te kunnen maken met een alternatief. ‘Broadcast’-communicatie laat elke servers tegelijkertijd weten dat er een switch plaatsvindt, oftewel ‘real-time batch switching’. Men zegt dat packet drops zeldzaam zijn, maar de betrouwbaarheid ten opzichte van unicast neemt dus iets af. Het is aan de gebruiker of de tijdswinst de moeite waard is.
Specifieke toepassingen voor de nieuwe broadcast-methode zijn volgens Fujitsu onder andere digital twins, generatieve AI en medicijnenonderzoek.
Toekomstige toepassing
Fujitsu heeft zelf een platform om geavanceerde AI-technologieën te testen, onder de codenaam Kozuchi. Daarop wil het bedrijf de CPU/GPU-optimalisatietechniek toepassen. De nieuwe communicatiemethode voor HPC-systemen hoopt Fujitsu in te zetten voor de 40-qubit quantumcomputersimulatie die het in aanbouw heeft.
Andere toepassingen zijn nog onzeker, maar het is mogelijk dat er software beschikbaar zal komen die de nieuwe uitvindingen breder inzetbaar zal maken.
Lees ook: Fujitsu integreert public clouddiensten volledig in overkoepelend concern