
MobileLLM werd uitgedacht voor smartphones, waar minder rekencapaciteit en energiebronnen ter beschikking staan. Achter het model zitten onderzoekers van Meta en PyTorch.
Het nieuwe LLM is er gekomen door optimalisaties door te voeren aan verschillende, kleine modellen. Deze modellen bevatten minder dan één miljard parameters en zijn daardoor geschikt voor toestellen waar de rekenkracht beperkt is, zoals bij smartphones.
Bij het uibrengen van nieuwe modellen ligt er altijd een grote nadruk op het aantal gebruikte parameters. Dit wordt meegegeven ter indicatie van de prestaties van het model, waarbij een groter aantal parameters snellere en meer gedetailleerde resultaten zou opleveren. Een model als GPT-4 zou naar schatting bijvoorbeeld meer dan een biljoen parameter bevatten.
Nieuwe benadering
MobileLLM is ontwikkeld door een samenwerking tussen Meta Reality Labs, Meta AI Research (FAIR) en PyTorch. MobileLLM is slechts een illustratie van een mogelijke aanpak om LLM’s voor smartphones te ontwikkelen. Geïnteresseerden kunnen met de resultaten en inzichten aan de slag om zelf een diepgaand en energiezuinig model te ontwikkelen. Meta gaf voor dergelijke doeleinden de trainingscode vrij.
Nieuwe onderzoeken kunnen daarnaast met de nieuwe inzichten aan de slag om opnieuw verbeteringen in dergelijke LLM’s aan te brengen. MobileLLM brengt verbeteringen van 2,7 tot 4,3 procent aan volgens benchmark-testen die het LLM vergelijken met voorgaande modellen van dezelfde omvang. Dat zijn significante verbeteringen, maar laat genoeg ruimte over voor toekomstige innovaties.
Prestaties evenaren miljarden-LLM’s
Voor zero-shot common sense reasoning-taken behaalde het geteste model met 350 miljoen parameters een accuraatheid die in de buurt komt van het LLaMa2-model dat uit 7 miljard parameters bestaat. In de komende tabel staan de resultaten weergegeven, de prestaties van het model met 350 miljoen parameters zijn te vinden in de grijze gestreepte balk.
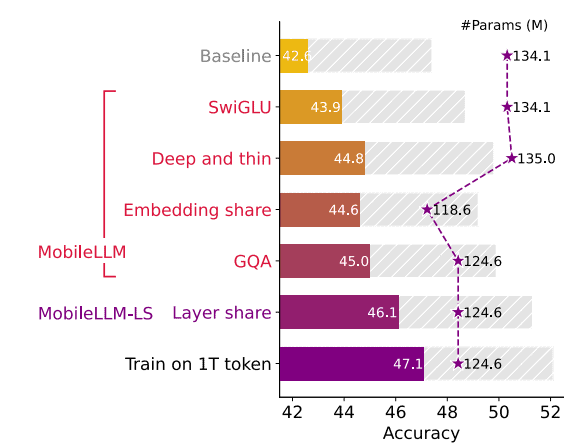
In MobileLLM zijn er twee belangrijke bevindingen die toekomstig onderzoek op weg kunnen zetten. Ten eerste werd er gevonden dat door het focussen op diepgang in plaats van grootte, de prestaties van het model verbeteren. Daarnaast blijken weight-sharing technieken significante voordelen op te leveren voor de opslag.
Tip! Anthropic start initiatief voor betere benchmarks voor LLM’s